Error Handling
Congratulations on making it through the first two weeks of spring quarter! We hope you are doing well, no matter where you are.
- Extra ownership practice
- Error handling: Motivating example
- Handling errors
- Handling nulls
- What should I take away from this?
Extra ownership practice: Will it compile?
Here are a few examples designed to refine your understanding of Rust’s ownership model. For each of these examples, think about:
- Will it compile?
- If not, why not? What could go wrong in an equivalent C or C++ program that does compile?
Ownership and mutability
Here’s our first example:
fn main() {
let s = String::from("hello");
s.push_str(" world");
}
This fails, because s is immutable by default, and push_str would mutate
the string.
In C and C++ (and most other languages), you need to explicitly designate
variables as immutable using const. In C++, a const string cannot be
mutated and would also have a compiler error. In C, the const keyword is a
real mess… const char* gets parsed as (const char)*, meaning you’re not
allowed to modify the destination buffer, but you could reassign that variable
to point to a different string. You can also write char* const, which does
the opposite: you can’t reassign the variable to point to a different string,
but you can modify the string buffer. If you want to get a true immutable
string, you have to use the type const char* const (or char const* const),
which which is just* just silly silly. (Demo
here) Also, const was introduced
later in C’s development, so const gets used very inconsistently throughout
the standard library, and it’s not uncommon to need to insert dubious casts to
get your code to compile.
To fix, we need to use the mut keyword:
fn main() {
let mut s = String::from("hello");
s.push_str(" world");
}
Let’s take a look at passing variables to functions. Does this code compile?
fn om_nom_nom(s: String) {
println!("{}", s);
}
fn main() {
let s = String::from("hello");
om_nom_nom(s);
}
This works! What if we add another om_nom_nom call?
fn om_nom_nom(param: String) {
println!("{}", param);
}
fn main() {
let s = String::from("hello");
om_nom_nom(s);
om_nom_nom(s);
}
The compiler complains about ownership here. Let’s break this down:
- On the first line of
main,sowns the string. - On the next line, ownership gets transferred to the
paramparameter ofom_nom_nom - When
om_nom_nomreturns,paramgoes out of scope, and ownership of the string hasn’t been transferred anywhere else, so the string is “dropped” and the string’s memory is freed. - Back in
main, on the third line, we try to usesagain. However, we previously gavesaway (and in factshas already been destroyed). The compiler complains with an error explaining this:error[E0382]: use of moved value: `s` --> src/main.rs:8:14 | 6 | let s = String::from("hello"); | - move occurs because `s` has type `std::string::String`, which does not implement the `Copy` trait 7 | om_nom_nom(s); | - value moved here 8 | om_nom_nom(s); | ^ value used here after move error: aborting due to previous error
Important note for understanding: I think a lot of people look at this demo
and think, oh my gosh, that’s annoying. Why does the compiler have to make
things so complicated? However, I would argue that this only looks silly
because it doesn’t have any mallocs or frees, and because the code is so
short. Let’s look at how we might have done this in C (keeping in mind that
String is a heap-allocated buffer).
We could have written the code like this:
void om_nom_nom(char* s) {
printf("%s\n", s);
}
int main() {
char* s = strdup("hello");
om_nom_nom(s);
om_nom_nom(s);
free(s);
}Or like this:
void om_nom_nom(char* s) {
printf("%s\n", s);
free(s);
}
int main() {
char* s = strdup("hello");
om_nom_nom(s);
om_nom_nom(s);
}Or like this:
void om_nom_nom(char* s) {
printf("%s\n", s);
free(s);
}
int main() {
char* s = strdup("hello");
om_nom_nom(s);
om_nom_nom(s);
free(s);
}Or like this:
void om_nom_nom(char* s) {
printf("%s\n", s);
}
int main() {
char* s = strdup("hello");
om_nom_nom(s);
om_nom_nom(s);
}Of these four possibilities, only one works without memory errors. Keep in mind that this is a trivial example, and real systems code is far more complex. 100+ line functions aren’t rare, and it’s not uncommon to have memory that is allocated in one place and freed 9 hours and 2000k lines of code later. It’s extremely important to maintain some notion of ownership, i.e. some notion of who is responsible for cleaning up resources.
Exceptions to ownership
What if we pass a u32 (unsigned int) instead of a String? Is this always an issue?
fn om_nom_nom(param: u32) {
println!("{}", param);
}
fn main() {
let x = 1;
om_nom_nom(x);
om_nom_nom(x);
}
This actually works fine! As mentioned on last Thursday’s lecture, the type
u32 implements a “copy trait” that changes what happens when it is assigned
to variables or passed as a parameter. We will talk more about traits next
week, but for now, just know that if a type implements the copy trait, then it
is copied on assignment and when passed as a parameter.
This is probably pretty confusing. How are you supposed to anticipate whether the compiler will copy a value when you pass it, or whether it will use ownership semantics? Unfortunately, you kind of just need to know about the types you’re using. The good news is that the vast majority of types aren’t tricky like this and use normal ownership semantics. Only primitive types + a handful of others use copy semantics.
References
Let’s talk about borrowing. How does this code look to you?
fn main() {
let s = String::from("hello");
let s1 = &s;
let s2 = &s;
println!("{} {}", s, s1);
}
This code works fine because s, s1, and s2 are all immutable. Remember,
you can have as many read-only pointers to something as you want, as long as no
one can change what is being pointed to. (We want to avoid the scenario where
chaos ensues because people are making sneak edits to the Google doc while
others are trying to read it over.)
What if we bring mutable references into the mix?
fn main() {
let s = String::from("hello");
let s1 = &mut s;
let s2 = &s;
println!("{} {}", s, s1);
}
This fails to compile because s is immutable, and on the next line, we try to
borrow a mutable reference to s. If this were allowed, we could modify the
string using s1, even though it was supposed to be immutable.
Let’s fix that by declaring s as mutable:
fn main() {
let mut s = String::from("hello");
let s1 = &mut s;
let s2 = &s;
println!("{} {} {}", s, s1, s2);
}
This fails again, but for a different reason.
- We first declare
sas mutable. 👍 - We borrow a mutable reference to
s. 👍 - We try to borrow an immutable reference to
s. However, there already exists a mutable reference tos. Rust doesn’t allow multiple references to exist when a mutable reference has been borrowed. Otherwise, the mutable reference could be used to change (potentially reallocate) memory when code using the other references least expect it.
Let’s remove the second borrow. Does this work?
fn main() {
let mut s = String::from("hello");
let s1 = &mut s;
println!("{} {}", s, s1);
}
- We first declare
sas mutable. 👍 - We borrow a mutable reference to
s. 👍 - We try to use
s. However, the value has been “borrowed out” tos1and hasn’t been “returned” yet. As such, we can’t uses.
Here’s the compiler error:
error[E0502]: cannot borrow `s` as immutable because it is also borrowed as mutable
--> src/main.rs:4:23
|
3 | let s1 = &mut s;
| ------ mutable borrow occurs here
4 | println!("{} {}", s, s1);
| ^ -- mutable borrow later used here
| |
| immutable borrow occurs here
The compiler is saying “hey, you borrowed s here, into s1. Now you’re
trying to use s, but you haven’t gotten the value back yet. I can’t give you
the value back yet, because s1 is still going to be used (as the second thing
being printed in that println).
How about this code?
fn main() {
let mut s = String::from("hello");
let s1 = &mut s;
println!("{}", s1);
println!("{}", s)
}
Unlike the previous example, this actually works. After the first println,
Rust sees that s1 will not be used again, so it “returns” the borrowed value
back to s. Then, when we try to use s, everything checks out. 👌
Here’s a question we got from a survey last year:
“One thing that’s confusing is why sometimes I need to &var and other times I can just use var: for example, set.contains(&var), but set.insert(var) – why?"
Can you answer this question based on your understanding of references now?
When inserting an item into a set, we want to transfer ownership of that item into the set; that way, the item will exist as long as the set exists. (It would be bad if you added a string to the set, and then someone freed the string while it was still a member of the set.) However, when trying to see if the set contains an item, we want to retain ownership, so we only pass a reference.
Error handling: Motivating example
To motivate our discussion, let’s imagine that we are dealing with a server that receives variable-length messages over a network. Each message has a header with metadata about how long the message is and where the various fields are inside of the messsage, followed by a payload containing the actual message data:
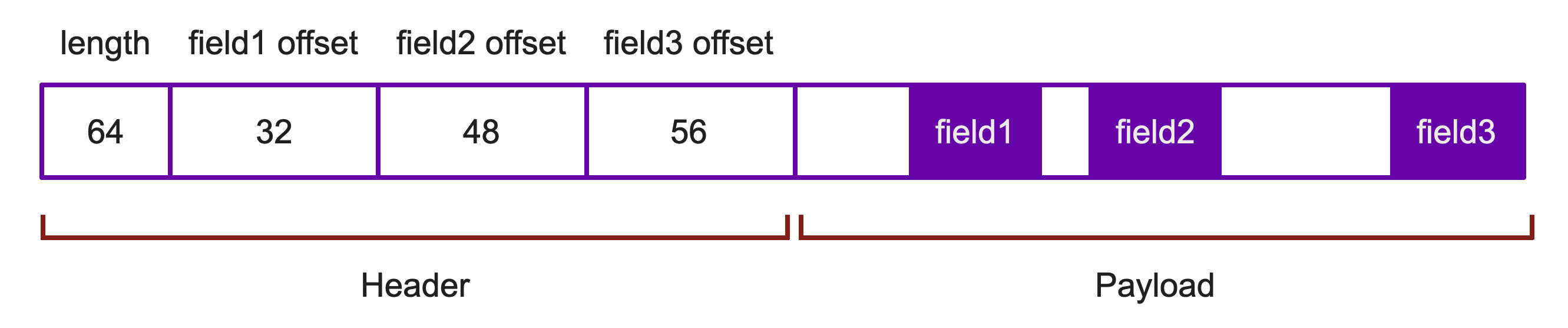
We might store such messages using the following struct:
struct message {
size_t length;
size_t field1_offset;
size_t field2_offset;
size_t field3_offset;
char payload[];
};
Then, we might begin processing the message by processing only field 1. We allocate space for a local copy of the message (e.g. maybe we’d like to mutate its fields as we process it) and copy over only field 1 for now:
// Processing part of a received message:
void *local_copy = malloc(message->length);
// Validate field1_offset is within the buffer (no buffer overflows!)
assert(message->field1_offset + FIELD_1_LENGTH <= message->length);
// Copy the field and process it
memcpy(local_copy + message->field1_offset,
message->payload + message->field1_offset,
FIELD_1_LENGTH);
process_field_1(local_copy + message->field1_offset);
Can you identify any weakness in this code? I argue that this code has some severe weaknesses that would allow for remote code execution.
First of all, there is definitely the possibility of integer overflows here. But even if we ignore that possibility, there is another issue that doesn’t have anything to do with overflows or underflows or any sort of mistake that we have been discussing so far.
The problem that I want to emphasize is that malloc can fail, and this code
doesn’t do error handling. If malloc fails to allocate memory (most likely
because there isn’t enough memory available), it returns NULL and sets
errno to indicate the error. Our code doesn’t realize this, and will memcpy
to local_copy + message->field1_offset, which is equal to
message->field1_offset since local_copy is 0. Since field1_offset is
specified by an attacker, the attacker can use this weakness to write any value
she wishes to any memory address she desires.
If this situation seems silly or contrived, know that code almost exactly the same as this has led to RCE in several real-world applications (see links in the “Handling Nulls” section).
There are two core issues at hand:
- The lack of a proper error handling system that makes it difficult to ignore when something has gone wrong
- The use of
NULLin place of a real value, which makes it hard to tell when we have an actual value and when we have a “there’s nothing here” placeholder
Handling errors
Error handling in C
C has an absolutely garbage system for handling errors. (It’s not really anything that’s built into the language; it’s more a convention on top of the language that people widely adopted, because there wasn’t anything better.) The system is typically this:
- If a function might encounter an error, its return type is made to be
int(or sometimesvoid*). - If the function is successful, it returns
0. Otherwise, if an error is encountered, it returns-1. (If the function is returning a pointer, it returns a valid pointer in the success case, orNULLif an error occurs.) - The function that encountered the error sets the global variable
errnoto be an integer indicating what went wrong. If the caller sees that the function returned-1orNULL, it can checkerrnoto see what error was encountered. You can see about half the possibleerrnocodes here.
As you might expect, a lot of issues have arisen from failing to check for
errors, or from having done it incorrectly. For example, this critical kernel
vulnerability allowed
attackers over the network to execute arbitrary code with kernel privileges.
The kernel had a set of functions that returned 0 on success and -1 on
error, but could also return NET_XMIT_CN (defined to be 2) to indicate
network congestion (not a failure condition, but potentially useful for the
caller to know about). Under congestion conditions, the code calling those
functions saw a nonzero return code, assumed network failure, and freed a bunch
of related memory. However, since the network hadn’t actually failed, that
memory was used again later: a use-after-free that led to remote code
execution.
The fix for this critical vulnerability? A one-line change:
--- a/drivers/infiniband/hw/cxgb3/iwch_cm.c
+++ b/drivers/infiniband/hw/cxgb3/iwch_cm.c
@@ -149,7 +149,7 @@ static int iwch_l2t_send(struct t3cdev *tdev, struct sk_buff *skb, struct l2t_en
error = l2t_send(tdev, skb, l2e);
if (error < 0)
kfree_skb(skb);
- return error;
+ return error < 0 ? error : 0;
}
Error handling in C++ and other common languages
Most other languages (including C++) use exceptions to manage error conditions. Exceptions work pretty well! However, they have some drawbacks. What are some downsides you can think of?
In my opinion, the biggest disadvantage is that failure modes are hard to spot. Any code can throw any exception at pretty much any time, and exceptions bubble up the stack until they’re handled (or until they reach the bottom of the stack, at which point the program will crash). That means you can call one function, and it might fail with an exception that was thrown by a totally unrelated helper function that is twelve function calls away. If you’ve worked on a large project, you have probably experienced cases where you deployed code you were happy with, but then it crashed in production, and you thought, whoops, I need to handle this exception too.
This problem compounds when you have a large codebase that is constantly evolving. Someone could modify a helper function to throw a new exception, and the code would compile fine, even if users of that function hadn’t added any new code to handle the new exception.
Exceptions are especially bad when combined with manual memory management (i.e. in C++). In handling an exception, you can forget to free memory, or accidentally double-free memory that was already freed before the exception was thrown, or you can end up with half-baked data structures if you caught an exception while initializing a struct and attempt to recover improperly.
As a concrete example, this function looks perfectly fine:
void process_input() {
char *buf = malloc(128);
// read input from user:
fgets(buf, 128, stdin);
// do more processing on input:
some_helper(input);
free(buf);
}
But it’s actually quite broken if used with exceptions in a C++ codebase:
void some_helper(string input) {
if (input == "uh oh") {
throw BadInputError("I don't like that");
}
}
int main() {
while (true) {
try {
process_input();
} catch (BadInputError) {
cerr << "That wasn't valid, try again" << endl;
}
}
}
You need the full context of the codebase to spot this problem, which is never a good quality for a large codebase to have.
For these reasons, and others related to performance, many large codebases (including Chrome/chromium and Firefox) ban the use of exceptions.
Enums
Before we can understand how Rust does error handling, we need to introduce a language feature called an enum. An enum (short for enumerated type) is a type that can store one of several variants. For example, we might use an enum to store a traffic light’s state:
enum TrafficLightColor {
Red,
Yellow,
Green,
}
let current_state: TrafficLightColor = TrafficLightColor::Green;
Enums are commonly used with match expressions. These are like switch
statements in C/C++/Java/Javascript, except the syntax is a bit nicer (no weird
breaks) and the compiler ensures that all possible variants are covered. If
you write the following code to control a car based on the traffic light state,
the compiler will produce an error:
fn drive(light_state: TrafficLightColor) {
match light_state {
TrafficLightColor::Green => println!("zoom zoom!"),
TrafficLightColor::Red =>
println!("sitting like a boulder!"),
}
}
error[E0004]: non-exhaustive patterns: `Yellow` not covered
--> src/lib.rs:8:11
|
1 | / enum TrafficLightColor {
2 | | Red,
3 | | Yellow,
| | ------ not covered
4 | | Green,
5 | | }
| |_- `TrafficLightColor` defined here
...
8 | match light_state {
| ^^^^^^^^^^^ pattern `Yellow` not covered
|
= help: ensure that all possible cases are being handled, possibly by adding wildcards or more match arms
= note: the matched value is of type `TrafficLightColor`
The following code covers all possible states, so it successfully compiles:
fn drive(light_state: TrafficLightColor) {
match light_state {
TrafficLightColor::Green => println!("zoom zoom!"),
TrafficLightColor::Yellow => println!("slowing down..."),
TrafficLightColor::Red =>
println!("sitting like a boulder!"),
}
}
FYI, if you’re only interested in one or two cases and you intentionally want to ignore the others, you can use a “default binding” as a fallthrough:
match light_state {
TrafficLightColor::Green => println!("zoom zoom!"),
_ => println!("do not pass go"), // default binding
}
Most common languages have enums. However, Rust enums are different in that they can store arbitrary data! For example, if you wanted to store someone’s location, you might have their GPS coordinates (in which case you’d want to store a latitude/longitude pair), or you might have their address (which you’d want to store as a string), or you might not have any specific location info. You can represent this as an enum:
enum Location {
Coordinates(f32, f32),
Address(String),
Unknown,
}
let location = Location::Address("353 Jane Stanford Way".to_string());
Then, if we have a Location and want to extract information from it, we can
do so using a match expression:
fn print_location(loc: Location) {
match loc {
// If the Coordinates variant matches, extract the (f32, f32) pair into
// two variables called lat and long:
Location::Coordinates(lat, long) => {
println!("Person is at ({}, {})", lat, long);
},
// If the Address variant matches, create a variable called addr
// containing the string that was inside the Address:
Location::Address(addr) => {
println!("Person is at {}", addr);
},
Location::Unknown => println!("Location unknown!"),
}
}
This feature is extremely useful in many contexts, and it turns out that we can apply it to error handling as well!
Error handling in Rust
We want functions to be able to return normal values if they succeed, but also
return errors if something went wrong. To do this, we can define a Result
enum with two variants:
- An
Okvariant that contains whatever value the function would like to return - An
Errvariant that contains information about any errors the function encounters
enum Result<T, E> {
Ok(T),
Err(E),
}
T and E are placeholders for specific types. For example, if a function
returns Result<String, MyErrorInfo>, then it will return Ok(some string) if
it runs successfully, or Err(an error object explaining the error) if it runs
into trouble.
Note that this Result type is part of the standard library, so you don’t need
to define it anywhere; you can just use it!
Here’s an example of how Result might be used:
fn gen_num_sometimes() -> Result<u32, &'static str> {
// ^ returns u32 if Ok, a string (error message) if Err
if get_random_num() > 10 {
Ok(get_random_num())
} else {
Err("Spontaneous failure!")
}
}
fn main() {
match gen_num_sometimes() {
Ok(num) => println!("Got number: {}", num),
Err(message) => println!("Operation failed: {}", message),
}
}
Comparing this to C
At face value, what we’re doing here is very similar to how C handles errors:
we’re returning one thing if everything succeeds (e.g. 0 in C or Ok in
Rust) and a different thing if something goes wrong (e.g. -1 in C or Err in
Rust). Have we actually improved anything?
We had two big problems with how C does error handling:
- It’s too easy to miss errors. If we forget to check errors, then our program will keep chugging along in a debhilitated state and can cause undefined behavior.
- Proper error handling is too verbose. It takes too much effort and typing to propagate errors when something goes wrong.
Rust’s version of error checking solves the first problem: it’s now obvious
from the function signature which functions can return errors, and the compiler
will verify that you do something with a returned error. Similar to how Rust’s
compiler forces you to think about ownership up front and address any possible
lifetime issues, usage of Result for error handling also forces you to think
about failure modes and address all possible error conditions (at least, all
error conditions that the compiler is able to find – it can’t find logic bugs
in your program). This can be very annoying, but if your program compiles, you
can be much more confident that you won’t hit an unexpected exception!
However, the second problem is still an issue. Consider this function, which
takes a filename, reads the file, and returns the contents of the file as a
String:
fn read_file(filename: &str) -> Result<String, io::Error> {
let mut s = String::new();
let result: Result<File, io::Error> = File::open(filename);
let mut f: File = match result {
Ok(file) => file,
Err(e) => return Err(e),
};
match f.read_to_string(&mut s) {
Ok(_) => (),
Err(e) => return Err(e),
};
return Ok(s);
}
(Note: this isn’t super idiomatic Rust code, but I’ve written it this way to
appear more similar to C++ code so that you can focus on the error handling
here. The week 2 exercises touch more on how Rust is an expression-based
language and how writing returns is often a bit different.)
Writing out these match statements is a lot of work for a little bit of
reward. To address this, the Rust language designers introduced the ?
operator.
The ? operator
If we have a Result, we commonly want to do the following:
- If the
ResultisOk(some value), extract the value from theOk - If the result is
Err(some error), propagate the error (i.e. return it to whoever called us)
The ? operator does this for us. We can write code like the following:
fn read_file(filename: &str) -> Result<String, io::Error> {
let mut file: File = File::open(filename)?;
// do other stuff...
}
File::open() returns Result<File, io::Error>. If we run this code and
File::open() returns Ok(some file), then the question mark operator will
extract the file object and store it in our file variable. Otherwise, if
File::open() returns an Err, the question mark operator will stop our
function immediately and make our function return the error. Concretely, the
question mark operator is transforming the above line into this code:
fn read_file(filename: &str) -> Result<String, io::Error> {
let mut file: File = match File::open(filename) {
Ok(f) => f, // unwrap the Ok() on success
Err(e) => return Err(e), // early return on error!
};
// do other stuff...
}
With this in mind, these two implementations are exactly equivalent:
// Long version (from before):
fn read_file(filename: &str) -> Result<String, io::Error> {
let mut s = String::new();
let mut f = match File::open(filename) {
Ok(file) => file,
Err(e) => return Err(e),
};
match f.read_to_string(&mut s) {
Ok(_) => (),
Err(e) => return Err(e),
}
return Ok(s);
}
// Short version, using ? operator:
fn read_file(filename: &str) -> Result<String, io::Error> {
let mut s = String::new();
let mut f = File::open(filename)?;
f.read_to_string(&mut s)?;
return Ok(s);
}
You can even use multiple ? operators within the same line to make code
really concise:
fn read_file(filename: &str) -> Result<String, io::Error> {
let mut s = String::new();
File::open(filename)?.read_to_string(&mut s)?;
return Ok(s)
}
Let’s focus on this one line:
File::open(filename)?.read_to_string(&mut s)?;
From left to right, this says:
- Call
File::open - If we got an
Errback, stop and return theErr - Otherwise, take the file object from the
Okand callread_to_stringon it - If we got an
Errback, stop and return theErr
This makes error propagation extremely easy, solving the other problem we had with C’s error handling.
Note that this code will not compile – why not?
fn read_file(filename: &str) -> String {
let mut contents = String::new();
File::open(filename)?.read_to_string(&mut contents)?;
return contents;
}
This is because the ? operator is being used in a function that returns
String. The ? is for propagating errors up the call stack, but this
function can’t return an error! What is supposed to happen if an error occurs
– does it just disappear into the void? The compiler doesn’t like that idea,
so it will give you an error that you’ll need to resolve.
Panics
What about errors that we don’t want to handle? There might be two good reasons for this:
- It might be a serious, unrecoverable error, and there’s simply no good way to handle the error
- It could be an error that we don’t ever anticipate happening, so we don’t want to put the effort into writing code to handle it
In these situations, you can panic. Panics terminate the program immediately and cannot be caught. (Side note: it’s technically possible to catch and recover from panics, but doing so really defeats the philosophy of error handling in Rust, so it’s not advised.)
To panic, use the panic! macro with an error message:
if sad_times() {
panic!("Sad times!");
}
Sometimes, a library function may give us an Err that we really don’t care to
handle in any graceful way, and we might want to convert this into a panic. For
example, if we are a terminal program and we fail to read input from the
terminal, there isn’t really anything graceful to do. If this happens, it’s not
worth the effort of continuing to propagate Errs up the stack for an error we
don’t care about handling.
In these situations, the Result::unwrap() and Result::expect(&str) methods
become extremely useful. These functions are sort of like the ? operator in
that they extract a returned value from an Ok() variant, but panic if we get
an Err() variant. For example:
// Panic if opening a file fails:
let mut file: File = File::open(filename).unwrap();
// Same thing, but print a more descriptive error message when panicking:
let mut file: File = File::open(filename).expect("Failed to open file");
// Panic if reading from stdin fails:
let mut input = String::new();
io::stdin().read_to_string(&mut input).expect("Failed to read from stdin”);
This isn’t a Rust class, and we aren’t going grade you based on your usage of
panics vs Result. However, we do want you to think about the implications of
calling unwrap/expect vs doing error checking and returning Result.
Handling nulls
NULL values appear all over the place, and not just in the context of errors;
for example, you can pass NULL as the second argument to waitpid to
indicate that you’re not interested in getting extra information about how a
process changed state. NULL seems innocuous at first glance, but Tony Hoare,
who invented the null reference in 1965, went on to call null references his
“billion-dollar mistake” because of
the problems they have caused. You can find a long list of security
vulnerabilities caused by NULL
here. Most of
them are denial of service vulnerabilities, but some of them result in
complete disclosure of information or remote code execution (e.g. this
critical Linux kernel vulnerability).
One remote code execution vulnerability very similar to the example we
discussed at the start of lecture occurred in Pidgin, which used to be a very
popular instant messaging app. (CVE link
here if you’re curious.)
Pidgin had a function called msn_slplink_message_find() that would retrieve
previously-received parts of a message. However, special types of messages
(“acknowledgement messages”) didn’t have any message contents;
message->buffer was set to NULL for these messages. When trying to
re-assemble received data, the msn_slplink_process_msg() function would call
msn_slplink_message_find() and then run
memcpy(message->buffer + offset, data, len), where an attacker can control
offset. However, message->buffer is NULL for special acknowledgement
messages! So, if an attacker can trigger this code on an acknowledgement
message, she can write anywhere she wants in memory.
Pidgin is far from the only one making this mistake. As another example, Adobe Acrobat Pro had a vulnerability that sounds extremely similar.
Taking a step back, why is it that null pointers so dangerous? I would argue
that the biggest issue is the cognitive burden they add for a programmer. If
you are implementing an API, you must remember which parameters might be NULL
and add code to handle these edge cases. If you are consuming an API, you must
ensure you never pass NULL when it might not be expected, and you must also
check return values when NULL might be returned. If the above links are any
indication, humans simply can’t do this reliably.
To solve this problem, we might want some way to indicate to the compiler when
a value might be NULL, so that the compiler can then ensure code using
those values is equipped to handle NULL.
Similar to Result, Rust does this with another enum called Option. A value
of type Option<T> can either be None or Some(value of type T):
enum Option<T> {
None,
Some(T),
}
For example, here’s a function that sometimes returns a String:
fn feeling_lucky() -> Option<String> {
if get_random_num() > 10 {
Some(String::from("I'm feeling lucky!"))
} else {
None
}
}
How can we use this returned value? Option has some pretty good
documentation that you
may want to check out, but here are a few things you can do:
- Like
Result(or any enum), you can use amatchexpression:match feeling_lucky() { Some(message) => { println!("Got message: {}", message); }, None => { println!("No message returned :-/"); }, } - You can call the
is_some()oris_none()methods to check whether theOptionis “null.” For example:if feeling_lucky().is_none() { println!("Not feeling lucky :("); } unwrapandexpectwork here as well:let message: String = feeling_lucky().unwrap(); let message: String = feeling_lucky().expect("feeling_lucky failed us!");- You can call
unwrap_or(default)to get the value of the option, usingdefaultas the default value if the option isNone.let message: String = feeling_lucky().unwrap_or(String::from("Not lucky :(")); - And, in a function that also returns an
Option, you can use the question mark operator:fn feeling_lucky_question -> Option<String> { let expanded_message: String = feeling_lucky()? + " Are you?"; // ^ will stop and return None early if feeling_lucky() returns None return Some(expanded_message); }Again, this only works in the context of a function that returns
Option.
What should I take away from this?
Error handling in Rust (and in general) is a big topic, and we could spend several lectures on it if we had the time. Sadly, we don’t. As such, we just want to give you the foundation for understanding how Rust approaches error handling, and to expose you to the motivation for why Rust decided to take this approach.
We will be implementing a linked list in lecture on Thursday to contextualize ownership mechanics and error handling. You’ll be able to see a practical example worked out in code; if you have questions, bring them to lecture or post on Slack!