Lecture 15: MapReduce
Building a search engine index
A search engine (like Google) has two primary functions: to crawl/download
pages from the internet (which you implemented in your archive assignment)
and to index those pages, so that given some search term, we can quickly find
documents containing that term.
The CS 106B way to populate a search index is simple:
- Declare an
unordered_map<string, vector<string>>, mapping search terms to a list of documents containing each term - Loop through the documents, and for each document, loop through the terms in
the document. For each term, do
map[term].push_back(document_id).
This works fine if the number of documents is manageable, but what if we’re trying to index the entire Internet? We certainly can’t fit all the documents on one computer’s hard drive, much less fit our index in memory. Somehow, we need to figure out a way to distribute our computation across a cluster of computers.
Google had several complicated, somewhat ad-hoc systems for building their search index, but they wanted a better solution. By 2004, they had come up with a simple and elegant way to break down the problem that could also apply to many other distributed computation problems.
The basic idea of MapReduce
We have some problem. It’s too big for us to solve on one computer.
Say we’re trying to launch a high-throughput bulk-production sandwich shop. We have a lot of raw ingredients, and we need to produce sandwiches as quickly as possible. We break this into three stages.
First, we distribute our raw ingredients amongst the workers in our shop. One person takes the tomatoes, one person takes the lettuce, one person takes the onions, and so on. We’ll call this the “map” stage.
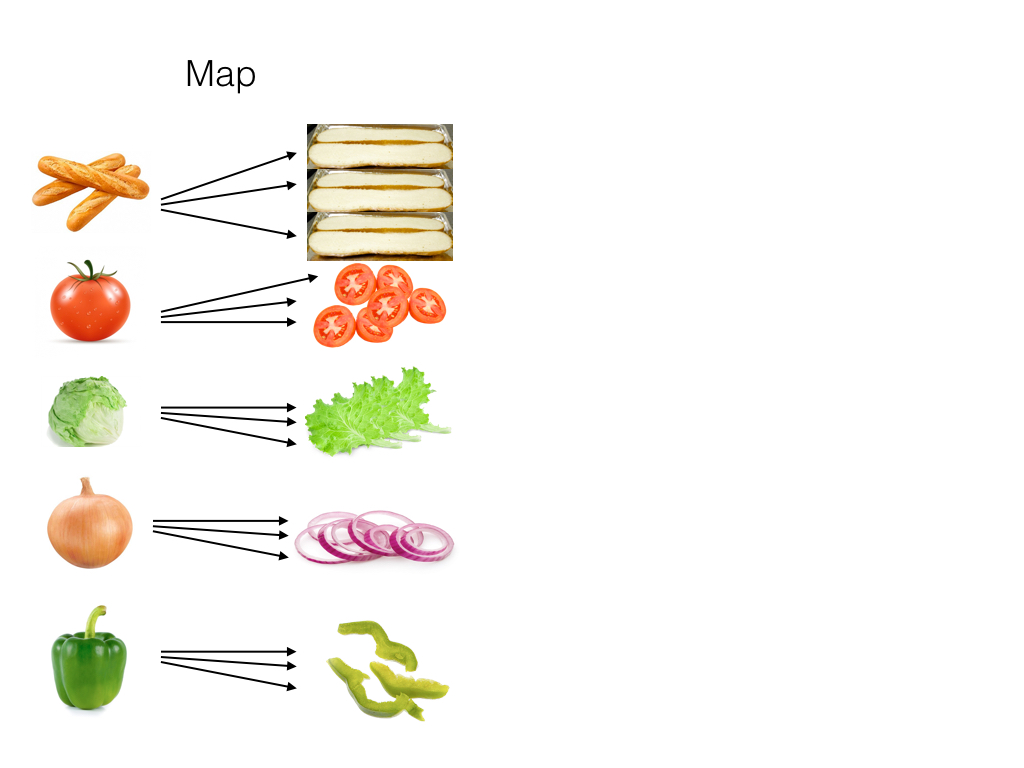
Next, we take these processed ingredients (which we’ll call “mapper intermediates”) and group them together into piles, so that making a sandwich becomes easy. We’ll call this the “shuffle/group” stage.
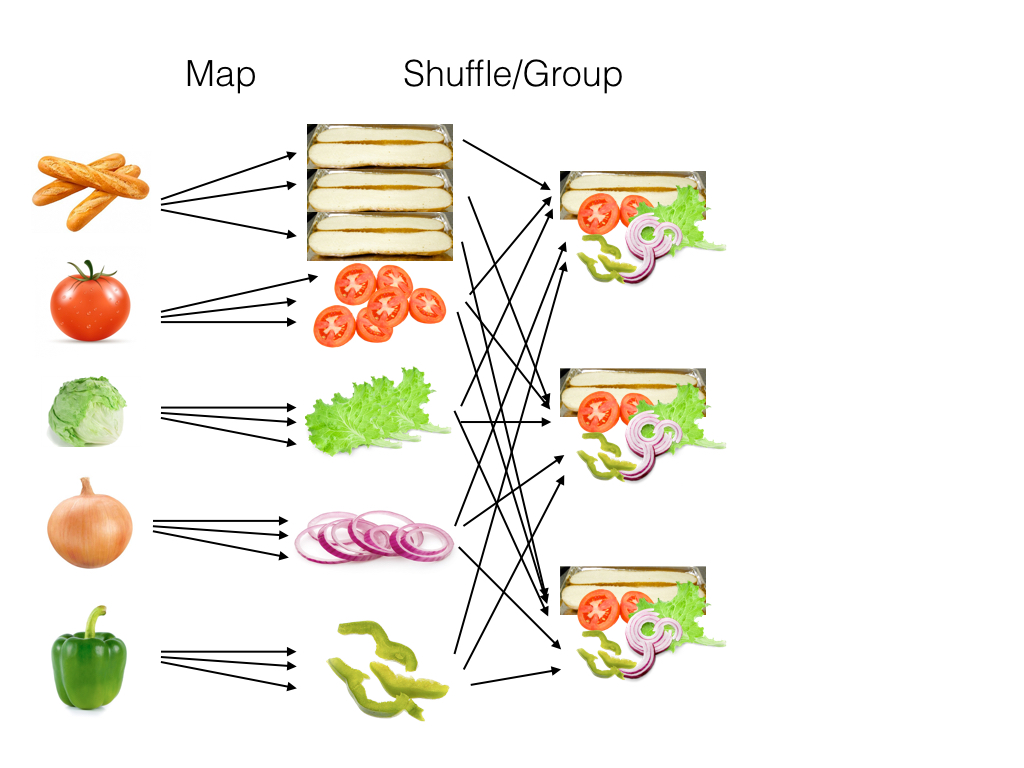
Finally, we’ll combine the ingredients into a sandwich. We’ll call this the “reduce” stage.
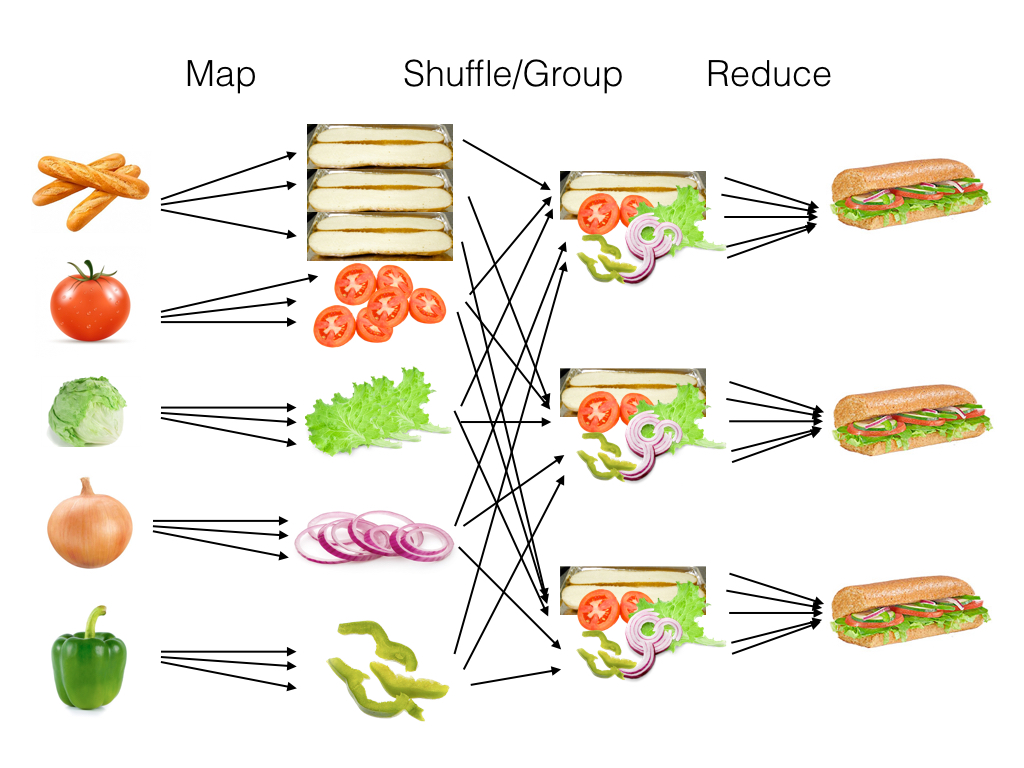
We can build a search index using the same idea. Instead of making sandwiches from ingredients, we’re trying to take raw documents and populate a data structure mapping search keywords to the documents they appear in (along with a count of how often they appear in each document):

In the map stage, we’ll take each document, and for every keyword in every document, we’ll print out a line mapping that keyword to the document.
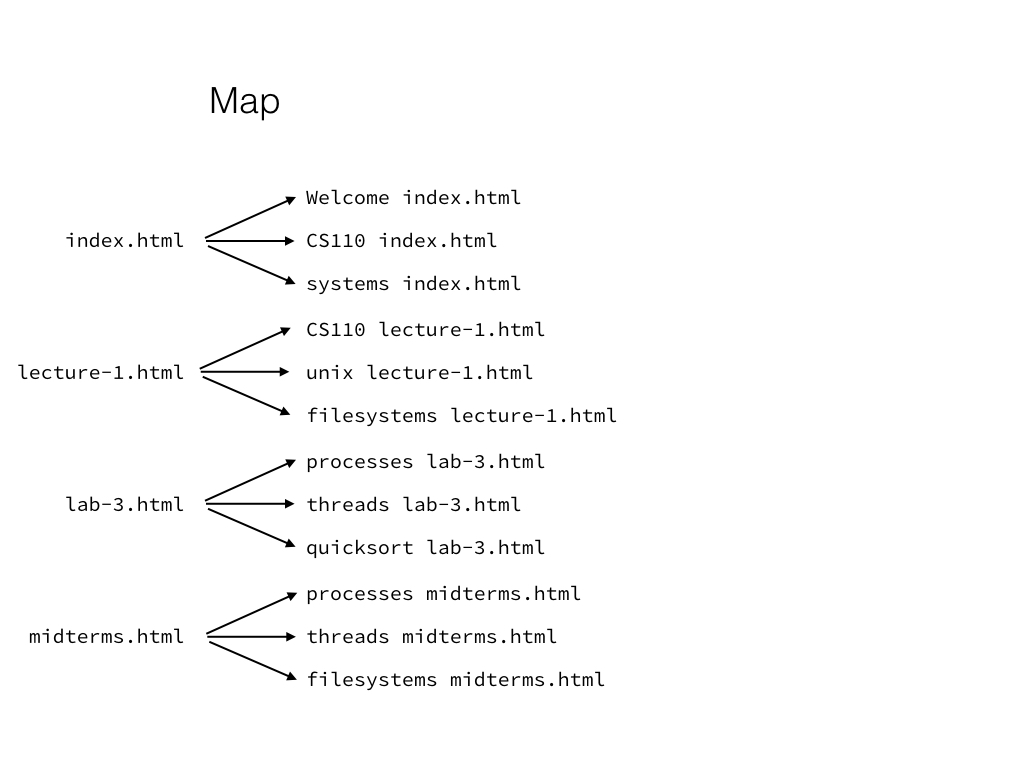
We shuffle and group the mapper intermediates by search keyword:
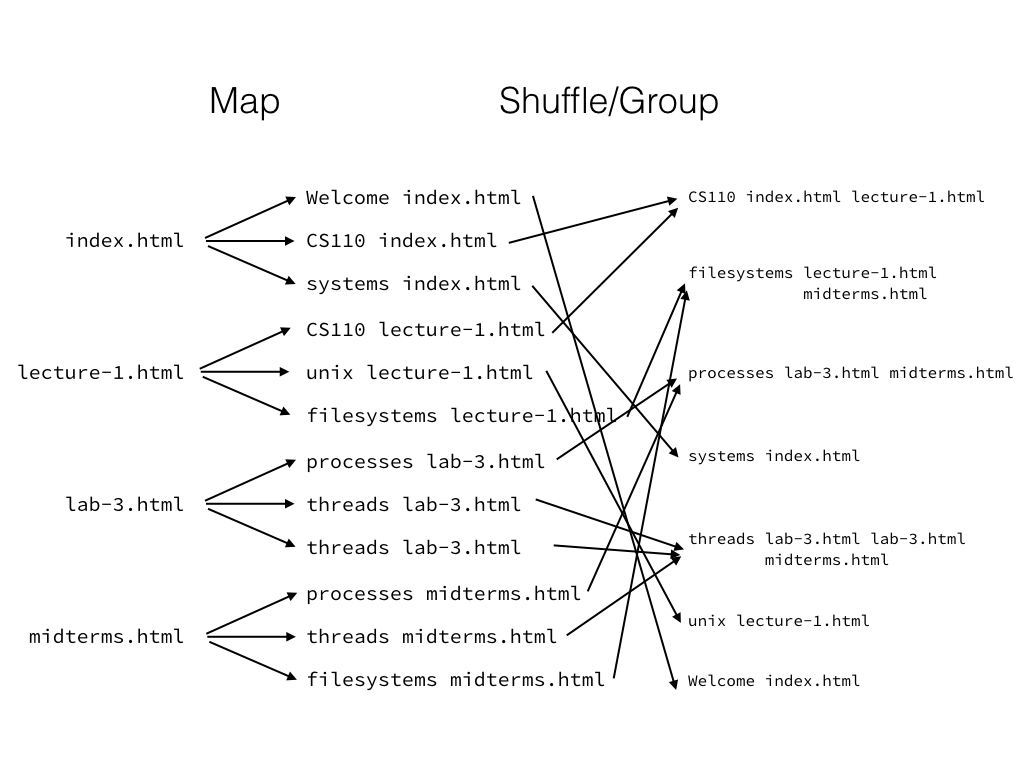
Finally, we reduce each line from the shuffle/group output into an item in our
index. Note that the shuffle output for threads had two instances of
lab-3.html, and the reducer reduces this into one “search result” with a
count of 2.

Implementing this in code
I have written very simple Python scripts that implement the mapper and reducer
for building this search index. You can see them in
/usr/class/cs110/lecture-examples/summer-2018/mapreduce.
The documents folder contains the inputs for our system. I have a series of
HTML documents downloaded from the course website:
$ cat documents/assign1.html
<html>
<head>
<link href="https://fonts.googleapis.com/css?family=Merriweather|Open+Sans|Anonymous+Pro" rel="stylesheet">
<link rel="stylesheet" type="text/css" href="../../review.css" />
<link rel="stylesheet" type="text/css" href="../../codemirror.css" />
<link rel="stylesheet" type="text/css" href="../../style.css" />
<title>CS 110: Principles of Computer Systems</title>
</head>
<body>
(more output omitted...)
I can run the mapper on this file. It takes an input HTML file, generates a
list of words in the file, and for each word, outputs a line
"<keyword> <filename>", as shown in the diagram above.
$ ./search-index-mapper.py documents/assign1.html mapper-intermediates
$ cat mapper-intermediates
CS documents/assign1.html
Principles documents/assign1.html
of documents/assign1.html
Computer documents/assign1.html
Systems documents/assign1.html
CS documents/assign1.html
Schedule documents/assign1.html
Piazza documents/assign1.html
Slack documents/assign1.html
Lecture documents/assign1.html
videos documents/assign1.html
Lab documents/assign1.html
signup documents/assign1.html
Gradebook documents/assign1.html
Assignment documents/assign1.html
Reading documents/assign1.html
UNIX documents/assign1.html
Filesystems documents/assign1.html
Thanks documents/assign1.html
to documents/assign1.html
Mendel documents/assign1.html
Rosenblum documents/assign1.html
for documents/assign1.html
this documents/assign1.html
wonderful documents/assign1.html
assignment documents/assign1.html
(more output omitted)
Let’s run the mapper on all of our input documents:
$ find documents/ -name "*.html" -exec ./search-index-mapper.py {} mapper-intermediates \;
Now that mapper-intermediates has been created with all the mapper outputs,
we can proceed to the shuffle/group stage. In the shuffle/group stage, we are
trying to group all of the lines related to a particular keyword. We can do
this easily by sorting the mapper intermediates (so that all lines starting
with a particular keyword are right by each other), and then running a very
simple Python script ./group-by-key.py to merge consecutive lines starting
with the same key. We end up with this:
$ cat mapper-intermediates | sort | ./group-by-key.py
aaabbbcccdddeeefffggghhhiiijjj documents/assign3.html
aab documents/lab-2.html
abandons documents/assign3.html
abcd documents/lecture-3.html
abc documents/assign3.html
abilities documents/assign4.html
ability documents/assign1.html documents/lecture-3.html
able documents/assign1.html documents/assign1.html documents/assign1.html documents/assign3.html documents/assign4.html documents/assign4.html documents/assign5.html documents/assign5.html documents/assign5.html documents/lecture-1.html documents/lecture-10.html documents/lecture-10.html documents/lecture-13.html documents/lecture-13.html documents/lecture-4.html documents/lecture-5.html documents/lecture-7.html
abnormally documents/assign3.html documents/lecture-3.html
abo documents/lecture-12.html
aboon documents/lecture-12.html
abort documents/lecture-5.html
Abort documents/lecture-5.html
about documents/assign1.html documents/assign1.html documents/assign1.html documents/assign1.html documents/assign1.html documents/assign1.html documents/assign2.html documents/assign2.html documents/assign2.html documents/assign2.html documents/assign3.html documents/assign3.html documents/assign3.html documents/assign3.html documents/assign3.html documents/assign3.html documents/assign3.html documents/assign3.html documents/assign3.html documents/assign3.html documents/assign4.html documents/assign5.html documents/assign5.html documents/assign5.html documents/assign5.html documents/assign5.html documents/lab-1.html documents/lab-1.html documents/lab-1.html documents/lab-1.html documents/lab-1.html documents/lab-1.html documents/lab-2.html documents/lab-2.html documents/lab-2.html documents/lab-3.html documents/lab-3.html documents/lab-3.html documents/lab-3.html documents/lab-4.html documents/lab-4.html documents/lab-4.html documents/lab-4.html documents/lab-4.html documents/lab-4.html documents/lecture-1.html documents/lecture-1.html documents/lecture-1.html documents/lecture-1.html documents/lecture-1.html documents/lecture-1.html documents/lecture-10.html documents/lecture-10.html documents/lecture-10.html documents/lecture-10.html documents/lecture-11.html documents/lecture-11.html documents/lecture-12.html documents/lecture-12.html documents/lecture-12.html documents/lecture-12.html documents/lecture-12.html documents/lecture-13.html documents/lecture-2.html documents/lecture-2.html documents/lecture-2.html documents/lecture-2.html documents/lecture-2.html documents/lecture-2.html documents/lecture-2.html documents/lecture-2.html documents/lecture-2.html documents/lecture-3.html documents/lecture-3.html documents/lecture-3.html documents/lecture-3.html documents/lecture-3.html documents/lecture-3.html documents/lecture-4.html documents/lecture-4.html documents/lecture-4.html documents/lecture-5.html documents/lecture-5.html documents/lecture-5.html documents/lecture-6.html documents/lecture-6.html documents/lecture-7.html documents/lecture-7.html documents/lecture-7.html documents/lecture-8.html documents/lecture-9.html
above documents/assign1.html
Above documents/assign1.html
above documents/assign4.html documents/assign4.html documents/assign4.html documents/assign5.html documents/assign5.html documents/assign5.html documents/assign5.html documents/assign5.html documents/lab-1.html documents/lab-1.html documents/lab-3.html documents/lab-3.html documents/lab-3.html documents/lab-3.html documents/lab-3.html documents/lab-3.html documents/lab-5.html documents/lab-6.html documents/lab-6.html documents/lecture-1.html documents/lecture-1.html documents/lecture-10.html documents/lecture-10.html documents/lecture-10.html documents/lecture-10.html documents/lecture-10.html documents/lecture-11.html documents/lecture-11.html documents/lecture-2.html
(more output omitted)
Finally, we can run the reducer, which takes each line, and for each line, prints documents with counts sorted by frequency.
$ cat mapper-intermediates | sort | ./group-by-key.py > grouped-output
$ ./search-index-reducer.py grouped-output final-output
$ cat final-output
aaabbbcccdddeeefffggghhhiiijjj documents/assign3.html:1
aab documents/lab-2.html:1
abandons documents/assign3.html:1
abcd documents/lecture-3.html:1
abc documents/assign3.html:1
abilities documents/assign4.html:1
ability documents/lecture-3.html:1 documents/assign1.html:1
able documents/assign5.html:3 documents/assign1.html:3 documents/lecture-10.html:2 documents/assign4.html:2 documents/lecture-13.html:2 documents/assign3.html:1 documents/lecture-4.html:1 documents/lecture-1.html:1 documents/lecture-7.html:1 documents/lecture-5.html:1
abnormally documents/assign3.html:1 documents/lecture-3.html:1
abo documents/lecture-12.html:1
aboon documents/lecture-12.html:1
abort documents/lecture-5.html:1
Abort documents/lecture-5.html:1
about documents/assign3.html:10 documents/lecture-2.html:9 documents/lab-1.html:6 documents/lecture-1.html:6 documents/lecture-3.html:6 documents/assign1.html:6 documents/lab-4.html:6 documents/assign5.html:5 documents/lecture-12.html:5 documents/lecture-10.html:4 documents/lab-3.html:4 documents/assign2.html:4 documents/lecture-4.html:3 documents/lecture-5.html:3 documents/lab-2.html:3 documents/lecture-7.html:3 documents/lecture-11.html:2 documents/lecture-6.html:2 documents/lecture-9.html:1 documents/lecture-8.html:1 documents/lecture-13.html:1 documents/assign4.html:1
(more output omitted)
We have our search index! Given some query, we can easily look up the document which contains that query term with the highest frequency.
(Note: This is an absolutely awful search index, but it works for demonstration purposes. If you want to learn about building a more reasonable search index, take CS 124.)
Scaling MapReduce
I ran the above code on one myth machine, and it took a full 2 seconds. That might not seem like much, but there were only 24 input documents, all of which were fairly small. It’s going to take an eternity for Google to index the entire Internet if they depend on only one machine.
Scaling the map phase is quite simple – just launch a bunch of mapper executables across many computers, and feed each one a subset of your input documents. If you have 100 input documents and 10 mapper workers, each will only have to process roughly 10 documents.
Scaling the shuffle/group and reduce steps is more tricky. To see why, let’s go back to the high-throughput sandwich shop example. Imagine you’re trying to produce sandwiches, but instead of having 5 ingredients, you have 50, and instead of producing just 3 sandwiches, you’re trying to produce 25. You can hire 10 people to process the 50 input ingredients, and the map stage will go perfectly fine. However, how should we now shuffle/group these 50 total piles of raw ingredients into 25 piles, one pile for each of our 25 output sandwiches? Let’s say you have 25 people hired to produce your output sandwiches (each fetches/groups the ingredients for a sandwich, then makes the sandwich itself). If each person has to go to each of the 50 piles to grab ingredients, your shop is going to be a mess. You might have one worker sifting through the pile of lettuce to find a nice piece, with twenty workers behind him waiting to grab some for their own sandwiches.
Here’s a better idea: When your mapper workers are processing an ingredient, instead of just creating one pile of mapper outputs, create several. Instead of making just one huge heap of lettuce, make 25 small bundles. Then, each of the 25 reducer workers can fetch their own bundle and quickly pull out a nice piece that they’d like to use.
The same discussion, applied to our search indexing problem:
Scaling the map phase is easy. We can launch a bunch of mappers in parallel,
and for every input file index.html.input, we can save the mapper output into
index.html.mapped. If the mapper workers are connected to a
distributed/networked filesystem (as every myth machine is), we can access
all of the mapper outputs together, even if they were produced from separate
machines.
Scaling the shuffle/group phase is less easy. In the search indexing problem,
our shuffle/group phase was to take all the mapper intermediates created from
all inputs, sort everything (so that like keys are nearby), and then group by
key (so that consecutive lines with matching keys are combined). In order to do
this, we have to concatenate all our mapper intermediates, but we might not be
able to do this on one computer. Our mapper intermediates for our 24 short
documents are 1.5MB; if we had 4 billion web pages (a random estimate from
here – I don’t know if it’s trustworthy,
but it’s a reasonable ballpark estimate), our intermediates would be at least
250 TB. We could try to enlist many reducer workers to do this process in
parallel, telling each reducer things like “you find all the lines starting
with keyword multithreading,” but even if we did that, each reducer would
have to sift through the entirety of the mapper intermediates (again, 250 TB)
looking for that keyword.
Here’s a better idea: When a mapper processes an input file index.html.input,
instead of producing one output index.html.mapped, split it into multiple
files index.html.0000.mapped, index.html.0001.mapped,
index.html.0002.mapped, and so on.
How should we divide the mapper outputs into these split-up files? It’s not a
good idea to simply put the first 100 lines in one file, put the next 100 lines
in the second file, put the next 100 lines in the third file, and so on; if you
do this, then a reducer looking for instances of multithreading still has
to look through all of the mapper outputs, because multithreading could
appear in index.html.0001.mapped just as easily as it might appear in
index.html.4928.mapped. Instead, have the mapper do this:
- For each keyword in
index.html.input:- Hash the keyword. We get back some hashcode (an integer). If we’re trying to split each mapper intermediate into 25 files, let’s take the hashcode mod 25.
- Write
<keyword> index.html.inputtoindex.html.<hashcode % 25>.mapped.
Note that under this scheme, if the keyword multithreading hashes to hashcode
3, it will only ever appear in *.0003.mapped files. If multithreading
is contained in index.html.input, we’ll see the related mapper output lines
in index.html.0003.mapped, but not in index.html.0005.mapped or
index.html.1827.mapped. This is significant; a worker reducing
multithreading will only ever pull input from *.0003.mapped.
Now, a reducer worker can concatenate *.<hash bucket num>.mapped, sort that,
group by key, and then run the reducer executable on that grouped output. For
example, one worker might concatenate index.html.0003.mapped,
lab-1.html.0003.mapped, assign-1.html.0003.mapped, and so on, then continue
the shuffle/group and reduce process as usual. This reducer worker is dealing
with 1/25th of the total mapper intermediate data, making the computation
tractable. (If more inputs are added to the system, increasing the size of the
mapper intermediate data so as to make this intractable again, we can just
increase the number of hash buckets.)
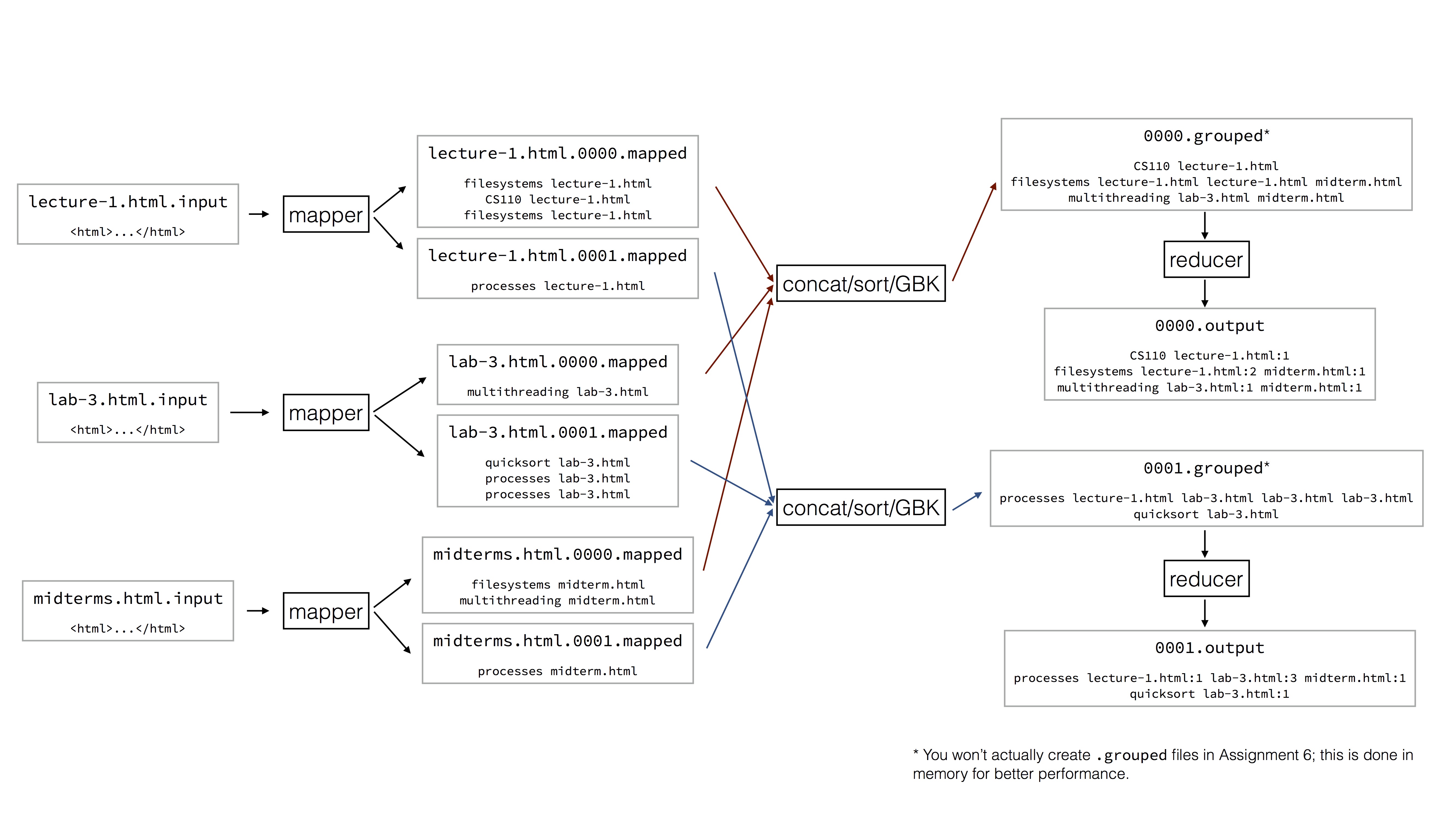
In this above example, we have 3 mappers and 2 reducers happily running in parallel. We could easily add more.
The draw of MapReduce: Versatility
The huge draw of MapReduce is that it can help distribute computations to solve problems completely unrelated to web indexing. If you can break your problem down into a map step and a reduce step (with a shuffle/group in between), you can use existing MapReduce infrastructure to solve the problem without having to write a new distributed computing system that deals with raw network connections, process management, etc.
Log analysis
Almost every web server maintains a log of connections. This is a snippet of access logs for a web server I run:
172.68.90.37 - - [30/Jul/2018:06:33:58 -0400] "GET /robots.txt HTTP/1.1" 404 151 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
172.68.90.103 - - [30/Jul/2018:06:42:14 -0400] "GET /.well-known/assetlinks.json HTTP/1.1" 404 151 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
162.158.167.123 - - [30/Jul/2018:06:48:53 -0400] "GET /wp-login.php HTTP/1.1" 301 193 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1"
162.158.167.213 - - [30/Jul/2018:06:48:54 -0400] "GET /wp-login.php HTTP/1.1" 404 151 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1"
172.68.146.107 - - [30/Jul/2018:06:48:54 -0400] "GET / HTTP/1.1" 301 193 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1"
162.158.167.213 - - [30/Jul/2018:06:48:55 -0400] "GET / HTTP/1.1" 200 1695 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1"
162.158.63.193 - - [30/Jul/2018:07:00:43 -0400] "GET /blog/2016/02/09/getting-started-with-web-development.html HTTP/1.1" 200 18606 "-" "Python/3.5 aiohttp/2.0.2"
Suppose you have some function which can take an IP address and a list of paths
that IP address accessed and determine the probability that the IP address is
malicious. (In the example above, I see 162.158.167.123 trying to access
/wp-login.php, which is extremely suspicious, because I don’t run WordPress
on my server, and because I know that out-of-date WordPress installations are
common targets for attackers.) How can we use the MapReduce paradigm to
generate probabilities of maliciousness in the following format?
172.68.90.37 0.01
172.68.90.103 0.01
162.158.167.123 0.95
162.158.167.213 0.95
172.68.146.107 0.08
162.158.63.193 0.12
- Mapper: For every log line, write
<IP> <path accessed>to the intermediate mapper output file - Running sort/group-by-key will produce
<IP> <list of paths accessed>for each unique IP - Reducer: Given a line in the form
<IP> <list of paths accessed>, call our security-analysis function to determine a probability, and write<IP> <probability of maliciousness>to our output
Precomputing the closest gas station to each point of interest
In Google Maps, you can type “gas station closest to Stanford University” and it will tell you the closest gas station. (It actually gives you a list, but let’s pretend it only gives you one.) You could run Dijkstra’s algorithm every time someone types in such a query, but this is likely too expensive to run on the fly. How might we precompute the closest gas station to every point of interest? (Yes, this would take a massive amount of disk space, but disk space is cheap to Google.)
- Mapper: For every gas station, iterate through every POI in a five-mile
radius. For each of those POIs, write
<POI> <gas station>:<distance>to the intermediate mapper output file. (Note: these intermediate files are going to be enormous.) - Running sort/group-by-key will produce
<POI> <station1>:<distance1> <station2>:<distance2> ...for each POI - Reducer: Given a line in the form
<POI> <station1>:<distance1> <station2>:<distance2> ..., sort the stations by distance and output<POI> <closest station>to our output file
Notes on MapReduce’s versatility
Note that MapReduce can be used to solve wildly varying problems from totally different domains, just by writing a mapper and a reducer. If you can split your problem into a map step and a reduce step, you can plug in your two basic executables and consider the job done.
Furthermore, the above mappers and reducers are pretty easy to write. We don’t have to think about multiprocessing, multithreading, networking, or any of the complicated infrastructure needed to distribute these massive computations amongst hundreds or thousands of machines. If our set of input data grows over time, we don’t even need to make any changes to the mappers or reducers we’ve written; we can just scale up our infrastructure.
This is the draw of MapReduce, and it’s why it got so much attention in the past decade!
Limitations
MapReduce is still being used by many companies (if you haven’t heard of MapReduce, you may have heard of Hadoop, which is an open-source implementation of the ideas I’ve described above), but many companies have since moved away. Google stopped using it to build its search index in 2014. These are the two biggest reasons:
- MapReduce is very much disk-based, and hard drives are slow. You can see how many files are involved in the “Scaling MapReduce” section above. Even worse, MapReduce depends on networked filesystems to run, and network latency can slow things down quite a lot. Newer systems make efforts to depend less on files.
- It’s very much oriented around batch processing: you have some huge set of input data, and you’re trying to process the entire thing in one shot. Google used it to rebuild its entire search index from scratch. It has virtually no support for stream processing: processing data in many small incremental steps. Many machine learning algorithms don’t fit into this two-stage batch processing paradigm, and other workloads have issues as well.
Despite these shortcomings, MapReduce has had huge influence on more recent systems, and is very much worth studying. It’s also a perfect capstone project for this class: it involves filesystems, multiprocessing, multithreading, and networking! I hope you enjoy implementing the MapReduce framework; it’s incredible that after just 7 short weeks, you’re in good shape to set up an industry-strength distributed computing system that once powered Google’s search index.